Machine Learning inference
Artificial Intelligence (AI) and Machine Learning (ML) are hot topics in the community. This feature enables you to expand the capabilities of your workers by running ML models in your models. For example, you can develop an application that uses image classification or text-to-speech.
To provide this feature, Wasm Workers Server relies on the WASI-NN proposal. This proposal defines a set of APIs to send and retrieve data, and run the ML inference at the host side. The main benefits of this approach are to reuse the existing ML ecosystem (like Tensorflow and OpenVINO) and use hardware acceleration when it's available (GPUs, TPUs, etc.).
Available backends
A backend or ML engine is an application that parses the ML model, loads the inputs, runs them and returns the output. There are multiple backends like PyTorch, Tensorflow (and Lite version), ONNX and OpenVINO™.
Currently, Wasm Workers Server only supports OpenVINO™ as ML inference engine or backend. The community is actively working on adding support for more backends, so you may expect new backends in the future.
Prerequisites
Install OpenVINO
Install the OpenVINO™ Runtime (2023.0.1):
Configure the OpenVINO™ environment:
Run ML inference in a worker
By default, workers cannot access the WASI-NN bindings. You need to configure it using the worker configuration file. For that, create a TOML file with the same name as the worker (like index.wasm and index.toml), and configure the WASI-NN feature:
name = "wasi-nn"
version = "1"
[features]
[features.wasi_nn]
allowed_backends = ["openvino"]
[[folders]]
from = "./_models"
to = "/tmp/model"
In this specific configuration, we assume you are mounting a _models folder that contains your ML models. You need to adapt it to your specific case.
Example
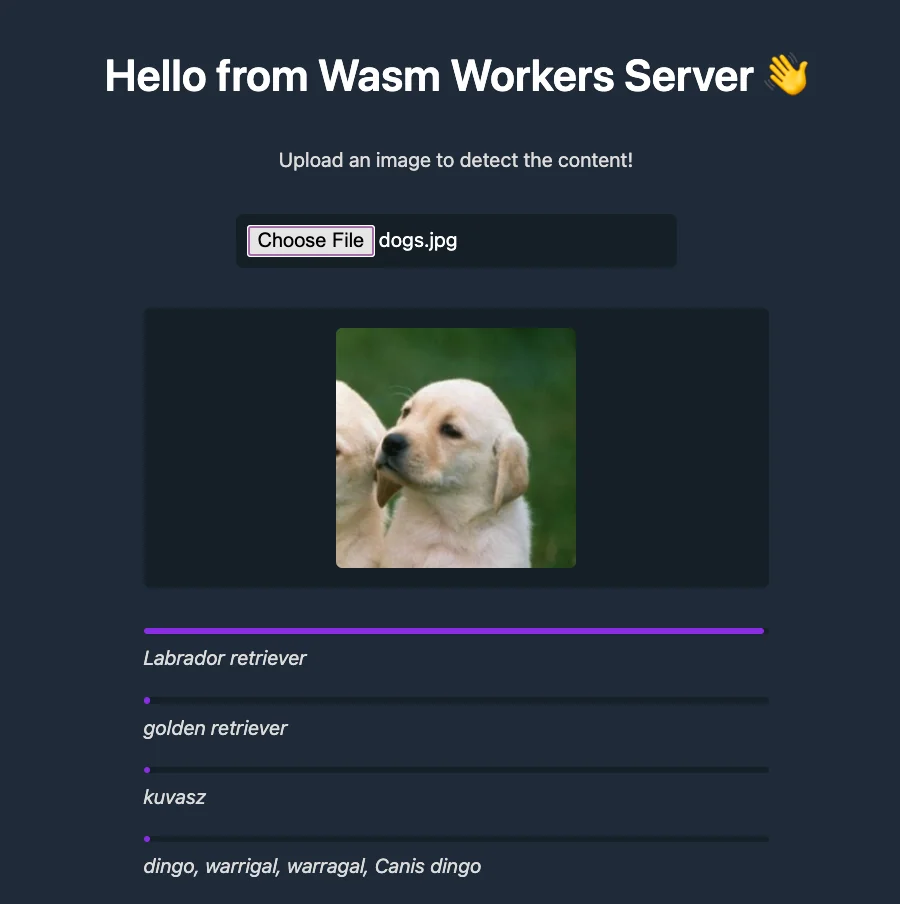
You can find a full working example in the project repository. In this example, you have a worker that returns a website to upload an image. When you upload it, a second worker retrieves the image and runs a MobileNet ML model to classify the content of the image.
We recommend to check this example to get started with ML and Wasm Workers Server.
Language compatibility
| Language | Machine learning inference |
|---|---|
| JavaScript | ❌ |
| Rust | ✅ |
| Go | ❌ |
| Ruby | ❌ |
| Python | ❌ |